Computer Vision Engineer / Sr. 3D GeneralistGet in touch
Proof of Concept · Diffusion Models
Single-Step Diffusion Detail Restoration
A proof of concept for restoring degraded face renders from 3D Gaussian splatting avatars. Fine-tunes SD-Turbo with LoRA adapters for paired image-to-image translation in a single forward pass.
About
The Problem
Gaussian splatting is becoming a leading approach for photorealistic avatar generation. But current splat-based avatars produce renders with visible artifacts: blurred facial features, loss of fine detail around eyes and mouth, hair strand merging, and inconsistent skin texture.
This proof of concept demonstrates that a single-step approach grounded on the existing render can restore detail at interactive speeds while preserving identity. The degradation pipeline is synthetic, designed as a proxy for real splat render artifacts. In production, training would use actual degraded/clean render pairs from the target avatar pipeline.
Results
0.205
LPIPS (Mean)
Perceptual similarity on 600 unseen test images
~80ms
Inference
Per image on an L40S. Single forward pass. ~1.6s on the live demo below.
~18.5M
Trainable Params
Out of ~860M total. Base SD-Turbo weights stay frozen.
Architecture
How It Works
The model adapts Stability AI's SD-Turbo for image-to-image restoration rather than text-to-image generation. The base model weights are frozen. Only LoRA adapters on the UNet and VAE decoder are trained, along with skip convolutions that bridge the encoder to the decoder at four resolution levels.
Encoder (Frozen)
The VAE encoder compresses the degraded 512x512 input into a 64x64 latent representation. Its weights are completely frozen during training.
UNet + LoRA (Rank 16)
The UNet processes the latent at timestep t=999, treating it as heavily corrupted and applying full restoration in a single step. LoRA adapters (rank 16) are added to the UNet attention layers. This is where the model learns the degraded-to-clean mapping.
VAE Decoder + LoRA (Rank 8)
The decoder reconstructs the output image from the processed latent. LoRA adapters (rank 8) fine-tune the decoder. Skip connections from the encoder feed spatial detail directly into the decoder at four resolution levels, initialized near-zero so they don't disrupt the pretrained weights early in training.
Loss Function
Three losses combined: L1 (weight 0.5) for pixel-level accuracy, LPIPS (weight 1.0) for perceptual similarity using VGG features, and Gram matrix (weight 0.07) for texture and surface detail. LPIPS leads the balance to push the model toward sharper, more visually correct outputs rather than blurry averages.
Results
Restoration Examples
Three examples showing the synthetically degraded input, the model's single-step restoration, and the original groundtruth side by side.
Degraded input
Model output
Groundtruth
1 / 3
Try It
Live Demo
Want to feed it your own image? The model is hosted on a Hugging Face Space below. The GPU sleeps when idle, so the first request takes 30–60s while it spins up. If you would rather skip the wait, the static restoration examples above show the same model's outputs.
Waking up the GPU — usually takes 30–60s
Data Pipeline
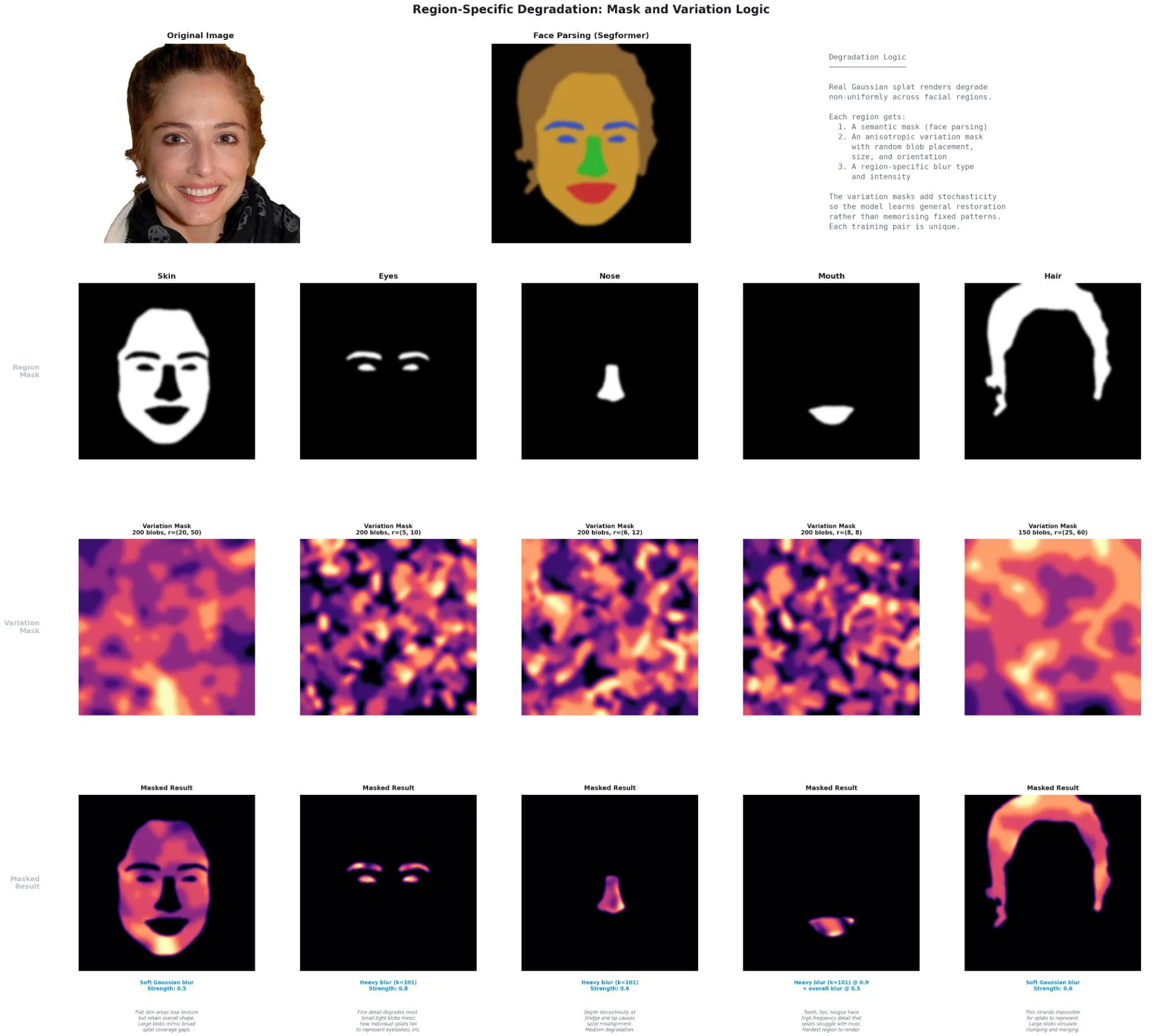
Region-Specific Degradation
A Segformer face parser segments each image into regions, and each region receives degradation calibrated to how splats typically fail there. Anisotropic variation masks keep the degradation patchy rather than uniform, mirroring how individual 3D Gaussians project differently by position, orientation, and scale.
The mouth region gets the heaviest degradation (0.9) because of depth discontinuities between teeth, lips, and tongue. Eyes receive 0.7 due to fine detail loss from competing splats in small areas. Hair gets 0.6 from strand clumping caused by splat merging. Nose and skin receive progressively less.
Training
Configuration
12,000
Training Images
CelebA-HQ at 512x512
600
Test Images
Unseen during training
5e-5
Learning Rate
500-step warmup, linear decay
FP16
Precision
Mixed precision training
L40S
Hardware
NVIDIA 48GB
0.3
Skip Dropout
On encoder-decoder connections
Scaling
Experiments
Multiple training runs were tracked in Weights and Biases, testing dataset size, LoRA rank, learning rate, skip dropout, and trainable layer count. Adjusting these hyperparameters collectively lowered the LPIPS score from 0.234 to 0.204 and confirmed that data diversity, regularisation, and adapter capacity were the main levers for generalisation.
Limitations
What This Doesn't Do
The face-parsing degradation approximates Gaussian splat artifacts from observed patterns but is not calibrated to any specific rendering engine. Production use would require training on real degraded and clean render pairs.
CelebA-HQ is a stand-in for actual avatar renders. It skews toward certain demographics and lighting conditions. A production system would need training data that matches the target pipeline's output distribution.
There is no temporal consistency across frames. Video enhancement would require additional constraints like optical flow warping and temporal losses. Resolution is fixed at 512x512.